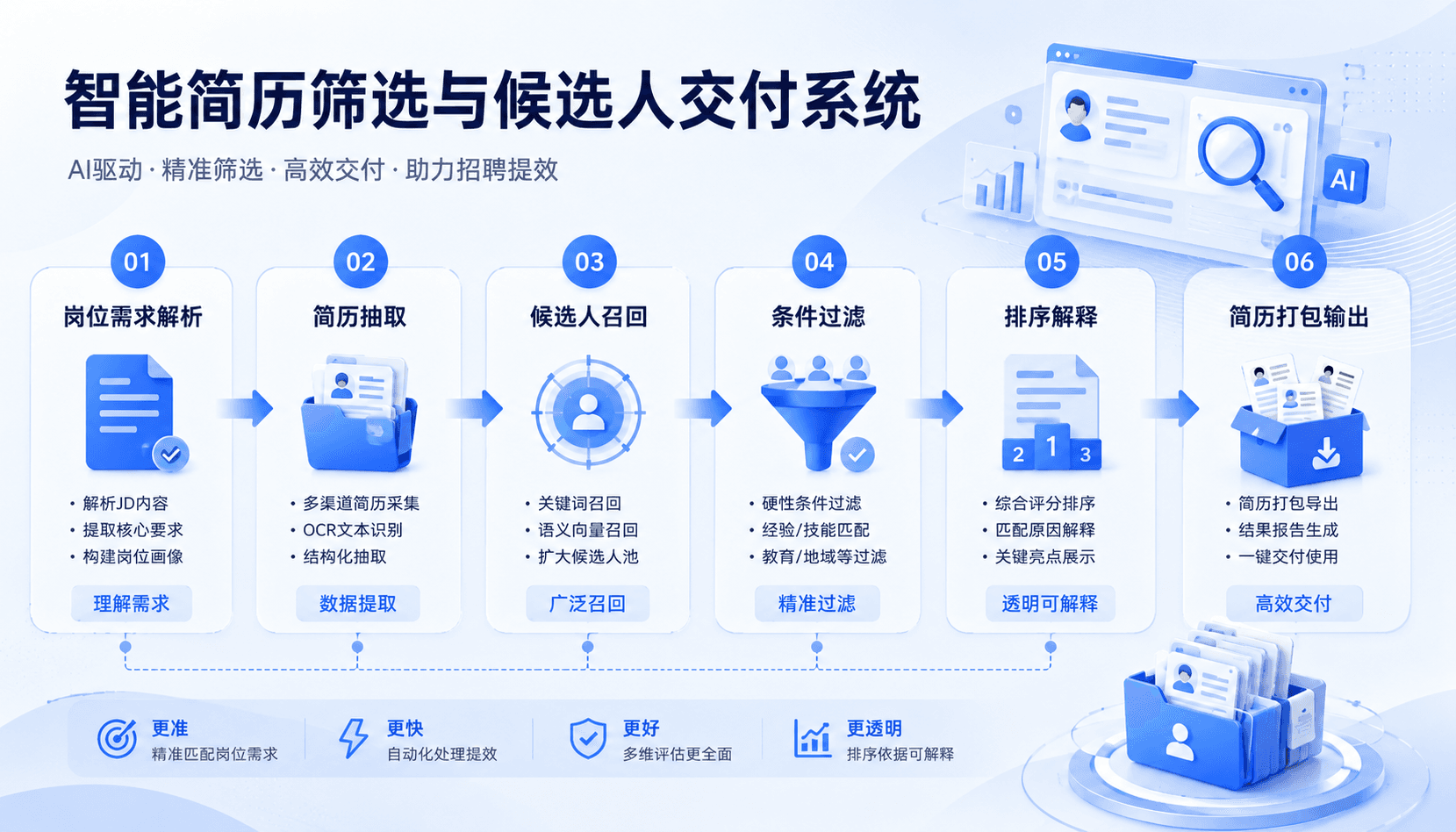
智能简历筛选与候选人交付系统
面向招聘场景的端到端智能筛选系统,覆盖 JD 解析、简历抽取、双路召回、规则过滤、排序解释与材料打包输出。
业务背景
招聘场景中简历筛选高度依赖人工,面对海量简历时效率低、标准不一致,且缺乏可解释的筛选依据和可追溯的审核记录。
我的职责
负责整体方案设计与核心链路实现,包括筛选漏斗架构、LLM 稳定性防线与可降级策略。
技术方案
- A.规则前置而非后置——确定性硬条件过滤放在向量召回之前,避免召回资源浪费
- B.双路召回 + RRF 融合——向量语义召回与关键词 BM25 召回互补,仅看排名不看绝对分数,天然归一化
- C.LLM 解释锚定已知事实——Prompt 强制引用规则命中项与技能交集,后置校验剔除幻觉
项目成果
- •支撑客户侧方案验证与试点推进,形成可复用的智能筛选解决方案
- •建立从筛选到交付的完整业务链路,覆盖岗位解析、候选人排序、人工审核与材料打包
技术方案详情
01.内容
# 人才筛选平台设计文档
日期:2026-05-11 状态:已审核
02.1. 项目概述
面向招聘场景的智能简历筛选与候选人交付系统。系统围绕岗位需求解析、简历内容抽取、候选人召回、规则过滤、排序解释和材料打包输出构建完整业务链路,支撑客户侧方案验证、试点推进与解决方案展示。
技术栈
| 层级 | 技术选型 |
|---|---|
| 后端框架 | Python / FastAPI |
| 前端框架 | React + Ant Design |
| LLM | MiniMax M2.7(Anthropic 兼容接口) |
| Embedding | Qwen3-Embedding-8B(OpenAI 兼容接口) |
| 结构化存储 | SQLite(开发期)→ PostgreSQL + pgvector(生产期) |
| 向量存储 | ChromaDB(开发期)→ pgvector(生产期) |
| 任务队列 | Redis + Celery |
| 文件解析 | PyMuPDF(PDF)+ python-docx(Word) |
| 文件存储 | 本地文件系统(开发期)→ MinIO(生产期) |
项目定位
实际业务系统,需考虑并发、容错、数据安全、可降级等生产要求。
03.2. 系统架构
2.1 架构模式
单体分层架构,前后端分离部署。
- •前端:React + Ant Design,独立部署
- •后端:FastAPI 单体服务,内部分 4 层(API → Service → AI → Data)
2.2 分层设计
API 层 → RESTful 接口、认证鉴权、请求校验
Service 层 → 业务逻辑、流程编排、规则引擎
AI 层 → LLM 调用封装、Embedding 封装、Prompt 管理、Schema 定义
Data 层 → ORM 模型、Repository 抽象、存储切换2.3 存储层
| 存储 | 用途 | 开发期 | 生产期 |
|---|---|---|---|
| 关系型 | 结构化数据(岗位/简历/筛选结果/审核日志) | SQLite | PostgreSQL |
| 向量 | 语义检索 | ChromaDB | pgvector |
| 缓存/队列 | 任务队列、结果缓存、限流、分布式锁 | Redis | Redis |
| 文件 | PDF/Word/ZIP 存储 | 本地 FS | MinIO |
存储切换通过 Repository 抽象层实现,换实现不换接口。
2.4 目录结构
talent-screening-platform/
├── backend/
│ ├── app/
│ │ ├── main.py # FastAPI 入口
│ │ ├── config.py # 配置管理(环境变量)
│ │ ├── api/ # API 层
│ │ │ ├── router.py # 路由聚合
│ │ │ ├── job.py # 岗位相关接口
│ │ │ ├── resume.py # 简历相关接口
│ │ │ ├── screening.py # 筛选相关接口
│ │ │ └── review.py # 审核相关接口
│ │ ├── services/ # Service 层
│ │ │ ├── jd_parser.py # JD 结构化解析
│ │ │ ├── resume_parser.py # 简历解析(PDF+Word)
│ │ │ ├── chunker.py # 语义结构分块
│ │ │ ├── candidate_recall.py # 双路召回 + RRF 融合
│ │ │ ├── rule_engine.py # 规则预筛引擎
│ │ │ ├── ranking.py # 粗排 + 精排
│ │ │ ├── confidence.py # 置信度评估
│ │ │ ├── explanation.py # LLM 匹配解释(事实锚定)
│ │ │ ├── packager.py # 材料打包输出
│ │ │ └── screening_pipeline.py # 筛选流程编排
│ │ ├── ai/ # AI 层
│ │ │ ├── llm.py # LLM 调用封装(重试/降级)
│ │ │ ├── embedding.py # Embedding 调用封装
│ │ │ ├── prompts/ # Prompt 模板
│ │ │ │ ├── jd_extraction.py
│ │ │ │ ├── resume_extraction.py
│ │ │ │ └── match_explanation.py
│ │ │ └── schemas/ # 结构化抽取 Schema
│ │ │ ├── jd_schema.py
│ │ │ └── resume_schema.py
│ │ ├── models/ # 数据模型(SQLAlchemy)
│ │ │ ├── job.py
│ │ │ ├── resume.py
│ │ │ ├── candidate.py
│ │ │ └── screening.py
│ │ ├── repositories/ # 数据访问层
│ │ │ ├── job_repo.py
│ │ │ ├── resume_repo.py
│ │ │ ├── vector_repo.py # 向量检索抽象
│ │ │ └── screening_repo.py
│ │ ├── rules/ # 规则插件
│ │ │ ├── base.py # 规则基类
│ │ │ ├── education_rule.py
│ │ │ ├── experience_rule.py
│ │ │ ├── location_rule.py
│ │ │ └── salary_rule.py
│ │ └── utils/ # 工具函数
│ │ ├── file_parser.py # PDF/Word 文本提取
│ │ └── zip_utils.py # 压缩包生成
│ ├── alembic/ # 数据库迁移
│ ├── tests/ # 测试
│ ├── .env.example
│ └── pyproject.toml
├── frontend/ # React + Ant Design
│ ├── src/
│ │ ├── pages/
│ │ │ ├── JobManage/ # 岗位管理
│ │ │ ├── ResumeUpload/ # 简历上传
│ │ │ ├── ScreeningResult/ # 筛选结果
│ │ │ ├── Review/ # 人工审核工作台
│ │ │ └── PackageDownload/ # 材料下载
│ │ ├── services/ # API 调用
│ │ └── components/ # 公共组件
│ └── package.json
├── data/ # 数据存储(gitignore)
│ ├── resumes/ # 上传的简历文件
│ ├── packages/ # 打包输出
│ └── chroma/ # ChromaDB 数据
└── docker-compose.yml04.3. 核心数据模型
3.1 Job(岗位)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| title | str | 岗位名称 |
| raw_jd | str | 原始 JD 文本 |
| parsed_jd | JSON | 结构化 JD |
| parsed_jd.skills | list[str] | 技能要求 |
| parsed_jd.experience_years | int | 工作年限 |
| parsed_jd.education | str | 学历要求 |
| parsed_jd.location | str | 工作地点 |
| parsed_jd.salary_range | dict | 薪资范围 |
| parsed_jd.keywords | list[str] | 关键词 |
| hard_rules | JSON | 硬性条件(供规则预筛) |
| soft_preferences | JSON | 软性偏好(供排序加权) |
| status | enum | draft/parsing/active/closed |
| created_at / updated_at | datetime | 时间戳 |
3.2 Resume(简历)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| file_path | str | 原始文件路径 |
| file_type | enum | pdf/docx |
| raw_text | str | 提取的原始文本 |
| parsed_data | JSON | 结构化数据 |
| parsed_data.name | str | 姓名 |
| parsed_data.skills | list[str] | 技能列表 |
| parsed_data.experience_years | int | 工作年限 |
| parsed_data.education | str | 学历 |
| parsed_data.location | str | 所在地 |
| parsed_data.salary_expectation | dict | 期望薪资 |
| parsed_data.work_history | list | 工作经历 |
| chunk_ids | list[str] | ChromaDB 中的 chunk 向量 ID 列表 |
| parsing_status | enum | pending/parsed/failed |
| extraction_stability | float | 抽取一致性(两次抽取差异度) |
| created_at | datetime | 时间戳 |
3.3 ScreeningTask(筛选任务)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| job_id | UUID | 关联岗位 |
| status | enum | pending/rule_filtering/recalling/coarse_ranking/fine_ranking/reviewing/completed/failed |
| recall_top_k | int | 召回数量,默认 50 |
| alpha | float | 规则/语义权重,默认 0.5 |
| filter_rules | JSON | 自定义过滤规则覆盖 |
| package_path | str | 打包输出路径 |
| trace_id | str | 全链路追踪 ID |
| error_message | str | 失败原因 |
| created_at / completed_at | datetime | 时间戳 |
3.4 CandidateResult(候选人结果)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| task_id | UUID | 关联筛选任务 |
| resume_id | UUID | 关联简历 |
| similarity_score | float | 语义相似度 |
| rule_match_rate | float | 规则匹配率 |
| skill_overlap_rate | float | 技能交集率 |
| field_completeness | float | 字段完整度 |
| coarse_score | float | 粗排综合分 |
| fine_score | float | 精排综合分 |
| matched_skills | list[str] | 命中技能 |
| missing_skills | list[str] | 缺失技能 |
| match_explanation | str | 匹配解释(LLM 生成,事实锚定) |
| explanation_verified | bool | 解释是否通过后置校验 |
| confidence | float | 置信度(0~1) |
| confidence_level | enum | high/medium/low |
| review_status | enum | pending/auto_approved/manual_approved/rejected |
| reviewer_note | str | 审核备注 |
3.5 AuditLog(审核日志)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | UUID | 主键 |
| candidate_result_id | UUID | 关联候选人结果 |
| action | enum | auto_approved/manual_approved/rejected/modified |
| operator | str | 操作人(system / user_id) |
| previous_state | JSON | 变更前状态 |
| new_state | JSON | 变更后状态 |
| reason | str | 原因(reject/modify 必填) |
| confidence_at_review | float | 审核时置信度 |
| created_at | datetime | 时间戳 |
3.6 实体关系
- •Job 1──N ScreeningTask(一个岗位可以有多次筛选任务)
- •ScreeningTask 1──N CandidateResult(一次筛选产出多个候选人结果)
- •Resume 1──N CandidateResult(一份简历可出现在多个筛选结果中)
- •CandidateResult 1──N AuditLog(一个候选人结果可有多条审核记录)
05.4. 核心筛选链路(v3)
4.1 链路总览
JD 结构化解析 → 规则预筛(硬条件前置)→ 双路召回(向量+关键词 RRF)→ 粗排 → 精排+置信度 → 分级审核(HITL)→ 材料打包漏斗式架构,每层收窄候选集,逐层减少下游计算量。
4.2 Stage 1: JD 结构化解析
职责: 将 JD 转化为可计算的结构化约束 + 语义查询向量
输入: 原始 JD 文本 / 自然语言招聘需求
处理: LLM + Schema 约束抽取,区分硬性条件和软性偏好
输出:
- •hard_rules:硬性条件(学历、年限、地域、薪资)→ 供 Stage 2 规则预筛
- •soft_preferences:软性偏好(加分项、优先条件)→ 供排序加权
- •jd_embedding:JD 语义向量 → 供 Stage 3 向量召回
- •skill_keywords:技能关键词列表 → 供 Stage 3 关键词路召回
兜底: 字段缺失标记为 optional,不阻塞流程。低确定性字段(如"熟悉大数据相关技术")不进规则预筛,仅作为软性偏好。
4.3 Stage 2: 规则预筛(硬条件前置)
职责: 在向量召回之前,用硬性规则从全量简历中排除明显不合格者
为什么前置: 向量召回无法保证"学历 ≥ 本科"这类硬约束,后置过滤会导致召回浪费
处理: SQLite 查询(学历、年限、地域、薪资)→ 命中候选集
规则引擎设计:
- •规则基类
BaseRule:定义evaluate(resume, jd) → RuleResult(passed, reason) - •具体规则继承基类:
EducationRule、ExperienceRule、LocationRule、SalaryRule - •规则插件化:新增规则 = 新增类,注册到规则引擎即可
- •规则可配置:每个岗位可选择启用/禁用哪些规则
关键: 这一步是确定性的,不依赖 LLM,零幻觉风险
4.4 Stage 3: 双路召回
职责: 从规则预筛后的候选集中,语义 + 关键词双路召回
路 1 向量召回: JD embedding → ChromaDB Top-K(语义相似)
路 2 关键词召回: JD skill_keywords → SQLite FTS5 BM25(精确匹配)
合并策略: RRF (Reciprocal Rank Fusion)
RRF_score(d) = Σ 1/(k + rank_i(d)) k=60为什么用 RRF: 向量分和关键词分不在同一量纲,直接加权无意义。RRF 只看排名不看绝对分数,天然归一化。
防误召回:
- •双路至少一路命中
- •向量召回结果用元数据 where 过滤(chunk_type 匹配)
- •召回后按 resume_id 聚合,同一简历多 chunk 命中加权
- •相似度阈值 cosine < 0.6 直接丢弃
4.5 Stage 4: 粗排
职责: 对召回候选人快速评分,筛选出精排候选
输入: RRF 融合后的 Top-30
评分模型:
coarse_score =
0.3 × 规则匹配率 (硬条件命中数/总数)
+ 0.3 × 语义相似度 (cosine)
+ 0.2 × 技能交集率 (JD技能∩简历技能 / JD技能数)
+ 0.2 × 字段完整度 (非空字段数/总字段数)输出: Top-15 进入精排
耗时: < 100ms,纯计算,不调 LLM
4.6 Stage 5: 精排 + 置信度评估 + 匹配解释
职责: 对粗排候选人逐个深度评估
输入: 粗排 Top-15
精排评分:
fine_score = α × 规则匹配分 + (1-α) × 语义匹配分
α 可按岗位配置,默认 0.5置信度计算(不依赖 LLM 自评):
- •高置信:硬条件全满足 AND 语义分 ≥ 70
- •中置信:硬条件部分缺失 OR 语义分 50~70
- •低置信:硬条件不满足 OR 语义分 < 50
LLM 匹配解释(事实锚定):
- •Prompt 强制要求引用已知事实(规则命中项/技能交集)
- •输出格式:matched_skills + missing_skills + experience_match + explanation
- •后置校验:LLM 输出的 matched_skills 必须与结构化抽取结果交叉验证,不一致则标记为幻觉剔除
输出: Top-10 + 匹配解释 + 置信度
耗时: ~2-5s(LLM 调用)
4.7 Stage 6: 分级审核(HITL)
分流规则:
- •高置信 → 自动通过,人工可选抽查
- •中置信 → 进入人工审核队列
- •低置信 → 建议拒绝,人工可翻案
审核工作台:
- •待审核队列按置信度排序,低置信优先展示
- •单条审核视图:简历原文 + 结构化字段 + 匹配详情 + LLM 解释
- •审核动作:approve / reject / modify / escalate
- •批量操作:支持批量通过/拒绝
审核日志: 所有审核操作记录 AuditLog(操作人/动作/状态变更/原因/时间),确保可追溯
4.8 Stage 7: 材料打包输出
输入: 审核通过的候选人列表
输出内容:
- •候选人简历原文(PDF/Word)
- •匹配报告 Excel(姓名/综合分/匹配项/缺失项/审核状态)
- •筛选摘要 JSON(机器可读,供下游系统对接)
格式: 岗位名_筛选报告_日期.zip
06.5. Chunking 设计
5.1 设计原则
按语义结构分块,而非固定长度。简历和 JD 都是人写的结构化文档,按章节切块才符合语义边界。
5.2 简历 Chunking
| Chunk 类型 | 内容 | 元数据 | 用途 |
|---|---|---|---|
| profile | 姓名/学历/年限/地域/薪资 | {resume_id, type: "profile"} | 硬条件过滤(不进向量库) |
| work_experience | 每段工作经历 = 1 chunk | {resume_id, type: "work", company, period} | 语义匹配核心 |
| project | 每段项目经历 = 1 chunk | {resume_id, type: "project", name} | 项目经验匹配 |
| skills | 技能列表完整保留 | {resume_id, type: "skills"} | 关键词精确召回 |
| education | 学历/院校/专业 | {resume_id, type: "education"} | 学历硬条件验证 |
5.3 JD Chunking
| Chunk 类型 | 内容 | 用途 |
|---|---|---|
| hard_requirements | 学历/年限/地域/薪资 硬性约束 | 规则预筛(不进向量库) |
| skill_requirements | 技能关键词列表 | 关键词路召回 |
| responsibility | 岗位职责/项目描述 | 语义召回 + 精排 |
5.4 关键设计决策
- •简历的 profile chunk 不进向量库,直接存结构化字段 → 规则预筛用
- •向量库只存 work_experience / project / responsibility chunk → 语义召回用
- •每个 chunk 携带 resume_id 元数据 → 召回后按 resume_id 聚合
- •单 chunk 超过 800 token → 按段落再拆分,子 chunk 继承父 chunk 的章节元数据
07.6. LLM 稳定性 — 六道防线
| 防线 | 机制 | 说明 |
|---|---|---|
| 1. Schema 约束输出 | Pydantic 定义输出 Schema | LLM 输出必须通过 JSON 校验,字段缺失/类型不对触发重试 |
| 2. 结构化重试 | 最多 3 次 | 每次重试在 Prompt 中附带错误信息引导 LLM 修正 |
| 3. 事实锚定 | Prompt 强制引用已知事实 | 解释只能引用规则命中项/技能交集,禁止自由编造 |
| 4. 后置校验 | 交叉验证 | LLM 输出的 matched_skills 必须与结构化抽取结果交叉验证,不一致标记幻觉剔除 |
| 5. Fallback 降级 | 跳过 LLM 解释 | 3 次重试仍失败 → 仅输出粗排分数 + 规则命中详情,标注"建议人工复核" |
| 6. 抽取一致性检查 | 两次抽取对比 | 同一简历抽取 2 次,关键字段差异超阈值 → 标记"抽取不稳定",进入人工审核 |
08.7. 可降级架构
系统不是 LLM 不可用就停摆。
| 故障场景 | 降级策略 |
|---|---|
| LLM 不可用 | 纯规则模式:硬条件过滤 + BM25 召回 + 粗排评分,跳过 LLM 解释,所有结果进入人工审核 |
| 向量库不可用 | 关键词单路召回,粗排仅用规则匹配分,标注"向量检索降级" |
| Redis 不可用 | Celery 切换为同步执行,缓存穿透到数据库,限流降级为本地计数 |
09.8. 异步任务架构
8.1 请求生命周期
- •前端发起筛选请求 → FastAPI
- •FastAPI 创建 ScreeningTask 记录 → 返回 task_id
- •异步推送 Celery 任务到 Redis 队列
- •Worker 逐阶段执行链路
- •每阶段更新 task status → 前端轮询/SSE 推送进度
- •链路完成 → 通知前端
8.2 Redis 角色
- •任务队列:Celery Broker
- •结果缓存:JD 解析结果缓存(相同 JD 不重复调 LLM)
- •进度追踪:task:{id}:progress
- •限流:LLM API 调用计数,防突发流量打爆配额
- •分布式锁:同一简历防止并发重复抽取
10.9. 五可能力矩阵
9.1 可维护
- •Repository 抽象隔离存储实现
- •Prompt 模板独立管理,版本可控
- •配置外置(权重/阈值/规则启用)
- •分层架构职责清晰
9.2 可解释
- •每个得分溯源到规则/字段
- •LLM 解释锚定已知事实,后置校验剔除幻觉
- •匹配/缺失项结构化输出
- •审核日志完整记录
9.3 可扩展
- •规则插件化(新规则 = 新类,注册即可)
- •评分权重按岗位配置
- •Chunking 策略可替换
- •存储层可切换实现
9.4 可观测
- •trace_id 贯穿全链路
- •每阶段结构化日志(输入/输出/耗时/错误)
- •关键指标:各阶段耗时、LLM 调用成功率、幻觉率、审核翻案率
- •异常告警(LLM 超时 / 抽取失败 / 向量检索异常)
9.5 可降级
- •LLM 不可用 → 纯规则模式
- •向量库不可用 → 关键词单路
- •Redis 不可用 → 同步执行
- •降级状态可感知、可记录
11.10. 风险点与改进方向
| 风险点 | 当前方案 | 改进方向 |
|---|---|---|
| 简历格式极端多样 | PyMuPDF + python-docx | 引入 OCR fallback 处理扫描件 |
| JD 描述模糊 | LLM 抽取时标记模糊度 | 低确定性字段不进规则预筛 |
| 向量模型领域适配 | 通用 Embedding | 积累数据后微调 Embedding 模型 |
| 规则引擎扩展性 | 规则硬编码 | 引入规则 DSL,支持业务人员配置 |
| 并发与性能 | 单 Worker | 批量并发 + 队列削峰 + Embedding 批量接口 |
12.11. 面试表达指南
11.1 最像真实企业项目的点
- •规则前置而非后置 — 确定性逻辑先行,LLM 用在最需要语义理解的地方
- •双路召回 + RRF — 不是只靠向量,关键词不能丢
- •LLM 六道防线 — Schema/重试/锚定/后验/降级/一致性检查
- •可降级架构 — LLM 挂了系统不死
- •分级审核 + 审计日志 — AI 推荐而非 AI 决策
11.2 最能体现 AI 工程化的点
- •Chunking 按语义结构分块 — 不是无脑 512 token 切
- •置信度不依赖 LLM 自评 — 用可计算信号综合评估
- •LLM 解释锚定已知事实 — Prompt 强制引用 + 后置校验
- •存储分层 + Repository 抽象 — 切换实现零改动
11.3 易被追问的点及回答
Q: 向量召回和规则过滤哪个在前? A: 规则在前。向量召回不能保证硬约束,后置过滤等于浪费召回资源。
Q: LLM 输出不稳定怎么办? A: 六道防线:Schema 约束 → 重试 3 次 → 事实锚定 → 后置校验 → Fallback 降级 → 抽取一致性检查。
Q: ChromaDB 能上生产吗? A: 开发期用 ChromaDB 零运维,生产期切 pgvector。通过 Repository 抽象层,换实现不换接口。
Q: 置信度为什么不让 LLM 自己打分? A: LLM 自评偏向中间值且波动大。我们用硬条件命中 + 语义分 + 字段完整度 + 召回一致性四个可计算信号综合评估,每个信号可溯源。
Q: LLM 完全挂了怎么办? A: 降级到纯规则模式,系统不会因为 LLM 不可用而停摆。